


Chapter 4 Code Generation
- Introduction
- Overview of CORBA IDL
- Architecture of an IDL Compiler
- Repetitive Application-level Code
- Architecture of idlgen
- Benefits of Code Generation
- Using Configuration in Code Generation
- Comparison with Annotations in Java 5
4.1 Introduction
There is a wide variety of domain-specific code generation tools that can generate repetitive code via a user-written template or script file. Often, such tools could be made more flexible by equipping them with a configuration-file parser. In this chapter, I illustrate this by describing a code generation tool that I developed.
Before describing the code generation tool, I first need to provide some background information.
4.2 Overview of CORBA IDL
There are many competing technologies that can be used to build client-server applications. One such technology, CORBA, is a standard for an object-oriented version of remote procedural calls.
One feature central to CORBA is the interface definition language (IDL). An IDL file serves a purpose similar to a Java interface or a C++ header file: it defines a public interface. More specifically, an IDL file defines the public interface(s) of a server application.
IDL provides primitive types such as boolean, short, long, float, char and string. IDL also provides constructed types, including struct (similar to a C struct), a union (similar to a variant record in Pascal), and sequence (roughly similar to a std::vector in C++ or an ArrayList in Java). All these types can be used as parameters to operations defined in an interface.
Each CORBA product provides an IDL compiler that translates the types defined in an IDL file into corresponding types in a programming language (most commonly C++ or Java, but some CORBA products support other languages, such as C, Ada, SmallTalk, Cobol, PL/I, LISP, or Python). Thus, for example, a C++ programmer can manipulate an IDL struct through its C++ representation, while a Java programmer can manipulate it through its Java representation. An IDL interface is translated into two types in a programming language: a client-side proxy class and a server-side skeleton class. When a client wants to invoke an operation on a remote object in a server process, the client invokes the operation on a local proxy object, which marshals the invocation request into a binary buffer, sends that buffer across the network to the server application, and waits for the reply. A server-side skeleton object unmarshals the incoming request, dispatches it to the target object, then marshals the reply and transmits it across the network to the client.
4.3 Architecture of an IDL Compiler
The architecture of a typical IDL compiler is shown in Figure 4.1. A parser analyses an input IDL file, performs semantic checks, and builds an in-memory representation, called an abstract syntax tree (AST), of what it has parsed.
Figure 4.1: Architecture of an IDL compiler
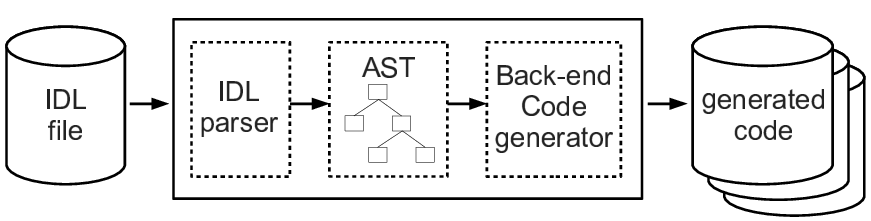
When parsing is finished, control is then passed to the back-end code generator. The code generator traverses the AST (perhaps several times) and uses print statements to generate code. By the way, that high-level architecture is not unique to IDL compilers; compilers for a great many languages are likely to share a broadly similar architecture.
4.4 Repetitive Application-level Code
In 1995, I started working in the consultancy and training department of a CORBA vendor (IONA Technologies), When working on consultancy assignments, I noticed it was common for CORBA server applications to contain significant amounts of repetitive code. For example, let’s suppose you want to put a CORBA server “wrapper” around a legacy system. If the legacy system has, say, 50 public operations, then you might define one or more CORBA IDL interfaces that, between them, contain a similar number of IDL operations. When you start to implement the CORBA server, you will quickly notice that each operation is implemented in a similar manner:
- Perform data-type translation to convert each input parameter from its IDL type to the corresponding legacy type.
- Then call the legacy operation that corresponds to the IDL operation.
- Finally, perform data-type translation to convert each output parameter from its legacy type to the corresponding IDL type.
It is not uncommon for there to be many thousands (or even tens of thousands) of lines of repetitive code in such server applications.
Writing thousands of lines of repetitive code by hand is error-prone and can quickly become a maintenance nightmare. I decided to design a code-generation tool that could automate the generation of such repetitive code.
4.5 Architecture of idlgen
The code-generation tool I developed became known as idlgen, which was a contraction of IDL code generator. The high-level architecture for idlgen is shown in Figure 4.2.
Figure 4.2: Architecture of idlgen
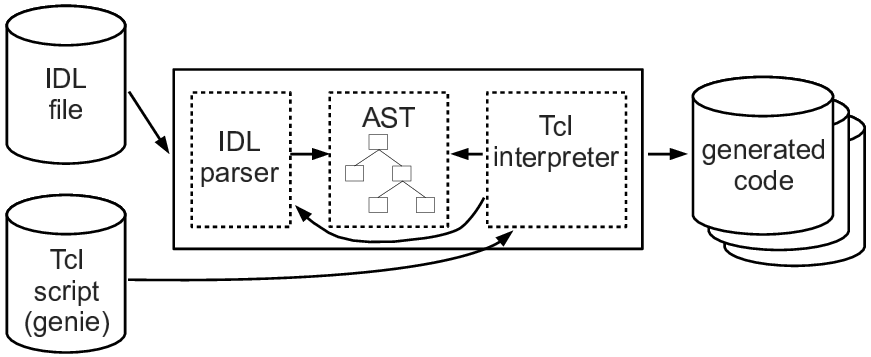
If you compare Figures 4.1 and 4.2, you will notice that idlgen has an architecture very similar to that of an IDL compiler. However, there are a few differences, as I now discuss.
The biggest difference is that idlgen replaces the fixed back-end code generator with an interpreter for a scripting language called Tcl.1 Doing this makes it possible to write a back-end code generator as a Tcl script. The term genie is used to refer to a “code genieration script”.
Another, but more minor, difference is that a genie is not “just” a back-end code generator to which control is passed after an input file has been successfully parsed. Instead, a genie (also) acts as the mainline of the code generator. It is the genie that calls the parser to parse an input IDL file. When parsing is complete, control returns to the genie, which can then traverse the AST and generate code. Allowing the genie to control the mainline provides some flexibility. For example, each genie can decide what command-line options it will support.
4.6 Benefits of Code Generation
I found that, when writing back-end code generators in Tcl, I was up to 100 times more productive than writing back-end code generators in C++. Obviously, a Tcl-based code generator was not as fast as one implemented in C++, but it was usually “fast enough”. For example, a genie would typically generate C++ code about five or ten times faster than a C++ compiler could compile that generated code. Thus, the relative slowness of a code generator implemented in an interpreted scripting language was never a bottleneck in application development.
In many of my consultancy assignments, I realised that the customer’s project would require significant amounts of repetitive code. In such cases, I might spend two or three weeks writing a project-specific genie that contained, say, 3000 lines of Tcl, and that genie would then generate the tens (or even hundreds) of thousands of lines of repetitive code required for the project.
My aim is not to engage in self-praise on the merits of idlgen. Rather, I simply offer it as an example of how, when a code generator is the right tool for the job, then it can significantly reduce the effort involved. I assume that many other domain-specific code generators provide similarly significant increases in productivity.
4.7 Using Configuration in Code Generation
You may be wondering, “What has idlgen got to do with Config4*?” The answer is that idlgen has two built-in parsers: one for IDL, and another for a predecessor of Config4*.2 The presence of this configuration parser greatly enhances the flexibility, and hence power, of idlgen. I explain why through the following example.
In Section 4.4, I explained how a project that puts a CORBA server wrapper around a legacy system might require a significant amount of repetitive code. Let’s assume you are working on such a project, and the IDL file you write for the CORBA server is similar to that shown in Figure 4.3.
interface Foo { void op1(...); void op2(...); ... void op20(...); void destroy(); }; interface Bar { void op21(...); void op22(...); ... void op50(...); void destroy(); }; interface Factory { Foo create_foo(...); Bar create_bar(...); }; interface Administration { string get_server_status(); void shutdown_server(); };
When the server application starts, it initially creates one Factory object and one Administration object. An administration client connects to the Administration object and invokes an operation to get information about the server’s status, or to ask the server to gracefully shutdown. Other client applications connect to the Factory object and invoke create_foo() or create_bar(), which results in the server creating a new Foo or Bar object on behalf of the client. (The “separate object for each client” approach might be for, say, auditing or security purposes). Then the client can invoke some of the operations on the newly created object. Between them, the Foo and Bar interfaces contain 50 operations (denoted as op1..op50 in the IDL file) that wrap correspondingly named operations in the legacy system. When the client is finished, it invokes destroy() to destroy the Foo or Bar object that the server had previously created for it.
When writing a genie to generate repetitive code for the project, you can code the genie so it parses not just an IDL file, but also a configuration file, such as that shown in in Figure 4.4.
interface_type = [ # name singleton/dynamic #-------------------------------------- "Factory", "singleton", "Administration", "singleton", "Foo", "dynamic", "Bar", "dynamic", ]; operation_type = [ # wildcarded name type #-------------------------------------- "Factory::create_*", "create", "*::destroy", "destroy", "Administration::*", "hand-written", "Foo::op1", "query", "Foo::op3", "query", "Foo::op8", "query", "Foo::op10", "query", "Foo::*", "update", "Bar::op27", "query", "Bar::op32", "query", "Bar::op33", "hand-written", "Bar::op30", "query", "Bar::*", "update", ]; code_segment_files = [ "some-code-segments.txt", "more-code-segments.txt", ];
Syntactically, the interface_type variable is a list, but its contents are arranged as a two-column table that maps the name of an IDL interface into a “type”: either singleton (meaning the server process contains only only instance of the specified interface) or dynamic (meaning that a create-style operation is used to create instances of this interface dynamically). Knowing this “type” of each IDL interface makes it possible for the genie to generate a main() function that creates one instance of each singleton interface (and does not create instances of dynamic interfaces).
The operation_type table specifies a “type” for each operation in all the IDL interfaces. To keep this table short, the operation name can contain "*", which is a wildcard that matches zero or more characters. For example, "*::destroy" matches both Foo::destroy and Bar::destroy (IDL uses "::" as the scoping operator). This enables the genie to use a cascading if-then-else statement to decide what kind of code to generate for the implementation of each IDL operation, as shown in the following pseudocode:3
foreach op in anInterface.listOperations() {
opType = op.getOperationType();
if (opType == "create") {
generate_create_operation(op);
} else if (opType == "destroy") {
generate_destroy_operation(op);
} else if (opType == "query") {
generate_query_operation(op);
} else if (opType == "update") {
generate_update_operation(op);
} else if (opType == "hand-written") {
opName = op.getFullyScopedName();
codeSegmentName = "implementation of " + opName + "()";
print(getCodeSegment(codeSegmentName));
} else {
error("unknown operation type: " + opType);
}
}
The assumption in the above pseudocode is that most create-style operations can be implemented using one kind of repetitive code, most destroy-style operations can be implemented using a second kind of repetitive code, and so on. There may be some operations that require hand-written code. If a code generation tool uses a general-purpose scripting language, then it should be possible to write a parser for what I call “code segment” files. Such a file contains a collection of named code segments. The syntax used in such a file is not important for the discussion at hand, but Figure 4.5 shows one possible format.
START: implementation of Bar::op33() ... // code that implements Bar::op33() END: implementation of Bar::op33() START: implementation of Administration::get_server_status() ... // code that implements Administration::get_server_status() END: implementation of Administration::get_server_status() START: implementation of Administration::shutdown_server() ... // code that implements Administration::shutdown_server() END: implementation of Administration::shutdown_server()
The code_segments_files variable in the configuration file specifies a list of code segment files. The genie can parse those files so that the cascading if-then-else statement shown earlier can copy-and-paste a code segment into the generated code for each operation that must be hand-written.
If a code generation tool does not enable scripts to parse a configuration file to access information such as that shown in Figure 4.4, then code generation scripts tend to be limited to generating the same type of repetitive code for every interface and every operation. But when, as is the case with idlgen, the code generator provides a parser for configuration files, code-generation scripts can become significantly more flexible. In my experience, scripts can become capable of generating all the repetitive code required for a project, rather than just a small subset of the code or “starting point” code that a programmer must then modify.
4.8 Comparison with Annotations in Java 5
I have explained how it can be useful for a code generation tool to have access to two types of information about data-types: (1) information provided by, say, an AST; and (2) extra information provided in a configuration file, such as that shown in Figure 4.4. Java 5 provides broadly similar functionality, as I now discuss.
A Java compiler converts a ".java" file into a ".class" file that contains bytecode plus type information. The type information in a ".class" file is conceptually similar to the information available in the AST of a compiler. Java’s reflection API makes it possible to navigate the type information stored in ".class" files. This makes it possible to use the reflection API to implement a code-generation tool. You can see this easily by comparing Figure 4.1 with Figure 4.6.
Figure 4.6: Reflection-based code generation in Java
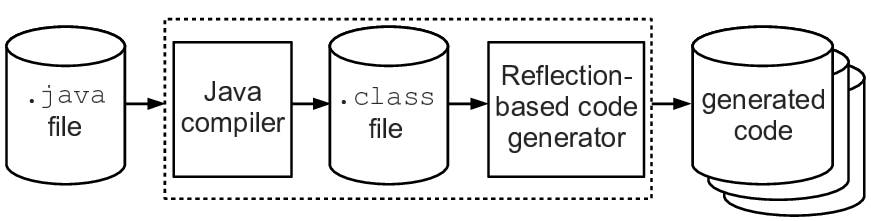
Version 5 of Java added several new features to the language, one of which is support for annotations. I will briefly describe the syntax and use of annotations, and then explain their relevance to code generation.
A commonly-encountered difficulty in adding a new feature to an existing programming language is that the new feature might require a new keyword, but introducing a new keyword would break existing programs that already use its spelling in identifiers. A (potentially ugly) solution to this problem is to overload the semantics of an existing keyword so it can be used for the new language feature. That was the approach taken by the designers of Java when adding annotations to the language. Java has always used the keyword interface to define an interface. Now, with Java 5, you can use @interface (the "@" symbol in front of the keyword is not a typo) to define an annotation. As an example, here is the definition of an annotation called @CodeGenType:
@interface CodeGenType {
String type();
}
The above defines an annotation, called @CodeGenType, that takes a String parameter called type.
Once an annotation type has been defined, you can instantiate the annotation at the start of the declaration of, say, an interface, class or operation. You can see examples of this in Figure 4.7.
@CodeGenType(type = "dynamic") interface Foo { @CodeGenType(type = "query") void op1(...); @CodeGenType(type = "update") void op2(...); ... @CodeGenType(type = "update") void op20(...); @CodeGenType(type = "destroy") void destroy(); };
Instantiating an annotation at the start of a declaration associates the instantiated annotation with the item being declared. The Java compiler can write details of instantiated annotations into the generated ".class" file. Then, a code generation tool like that shown previously in Figure 4.6 can use Java reflection to access the instantiated annotations associated with declarations.
Look again at the code-generation configuration file in Figure 4.4. In particular, notice that the interface_type table specifies that Foo is a "dynamic" interface. That configuration information is reproduced by the Java annotation on the Foo interface in Figure 4.7. Likewise, the type information specified for operations of Foo in the operation_type table in Figure 4.4 is reproduced by Java annotations in Figure 4.7. Thus, we see that metadata for code generation can come from either a configuration file or from annotations embedded in an input file. Both approaches seem to offer similar functionality.
Is it a good idea for a programmer to put metadata about a program in source-code files (as is the case with Java annotations)? Or should the programmer put the metadata in a separate file (such as a configuration or XML file)?
I have written many idlgen genies that parsed configuration files to obtain metadata about IDL interfaces. In those genies, the metadata indicated important characteristics about the type of code that should be generated. In other words, the metadata specified high-level implementation details. Implementation details do not belong in the specification of an interface. Therefore, it was entirely proper for the metadata to be written somewhere other than in IDL files.
Just as (metadata about) implementation details do not belong in the definition of a CORBA IDL interface, I feel that such metadata do not belong in an Java interface either. However, Java annotations are often used in a class rather than in an interface. And since a class does contain implementation details, it seems reasonable for annotations to appear there.
I do not hold a strong view about whether it is best to store metadata in source-code files or in separate configuration files. Perhaps the decision should be made on a case-by-case basis. If so, then it would be useful for future language designers to equip their languages with: (1) something akin to Java annotations that can be embedded in source-code files; and (2) a standardised way to store metadata in, say, a configuration file. In this way, programmers could mix-and-match the two approaches in whatever way best suits their needs.
- 1
- Here are some details for interested readers. The Tcl interpreter is packaged as a library of C functions, and the library contains a hash table that provides a mapping from the name of a command to a C function that implements the command. You can extend the Tcl interpreter with a new command called, say, foo, by writing a C function that implements the desired functionality, and then registering that C function with the name foo in the Tcl interpreter’s hash table. Once you have done that, the (now extended) Tcl interpreter can execute scripts that contain the foo command. When implementing idlgen, I used this technique to put a Tcl wrapper around the parser, and Tcl wrappers around each node in the AST produced by the parser. I chose Tcl because, at the time, it was one of the few scripting languages that had been designed to be extensible. Since then, scripting languages that are designed (or retrofitted) to be extensible are more common. If I were designing idlgen today, then I might be tempted to use Python or Lua instead because they are arguably better scripting languages and have a less unusual syntax.
- 2
- This predecessor supports a very limited subset of Config4*’s syntax: only name=value (where the value could be a string or a list of strings), scopes and an include command.
- 3
- Some scripting languages make it possible to use polymorphism (instead of a cascading if-then-else statement) to call one of several procedures. This technique can result in shorter, easier-to-maintain code. For example, the Tcl syntax is: generate_${opType}_operation $op. However, I have shown a cascading if-then-else statement for simplicity of discussion.